Among different machine learning algorithms, Xgboost is one of top algorithms providing the best solutions to many different problems, prediction or classification. The major objective of this post is to explore how categorical encoding methods affect Xgboost model performance.
- Xgboost Model + Target Encoding for categorical variable
- Xgboost Model + Label Encoding for categorical variable
- Xgboost Model + One Hot Encoding for categorical variable
- Neural Network + Entity Embedding for categorical variable (primary task is to provide entity embedding matrix of categorical variable for Xgboost model)
- Xgboost Model + Entity Embedding for categorical variable
Xgboost
Personally, Xgboost is always the first algorithm of choice in any data science and machine learning hackathon. It is not only providing you an high accuracy, but also saving time. It becomes one of the most popular machine learning algorithm for its powerful, robust and straightforward privileges.
It is not sufficient to only rely upon single machine learning model’ result. Decision tree based ensemble machine learning algorithm offers a systematic methodology to ensemble multiple weaker learners. Xgboost belongs to decision tree based ensemble machine learning family and created by Tianqi Chen. Not like bagging ensemble method, all the trees are parallel, for Xgboost, all the trees are built sequentially. For each tree, the finally purpose is to reduce the residual error comparing previous tree. Hence, the tree that grows next in the sequence will learn from an updated version of the residuals.
The three key hyper parameters of xgboost are:
learning_rate: default 0.1
max_depth: default 3
n_estimators: default 100
Neural Networks
Neural networks, inspired by biological neural network, is a powerful set of techniques which enables a computer to learn from historical data. Neural networks include different layers, the leftmost layer is called the input layer, and the rightmost layer is called output layer. Except input layer and output layer, the middle part called hidden layer (layers). On each layer of neural network, there are multiple nodes known as sigmoid or relu neurons, and individual node might be connected to several nodes in the previous layer, and it also receives data, and several nodes in the next layer, to which it sends data. Each data will multiple a number which is known as ‘weight’ and plus a number which is known as ‘bias’, and finally yield a single number, there is a thresh hold value to filter this single number, if the number exceed the thresh hold value, the node ‘fires’ then it will send the number along all its outgoing connections.
Categorical data
In many data science projects, there are two major data types: numerical data type and categorical data type. However, the big difference for numerical data type and categorical data type is that numerical data have meaning as a measurement, and it does not matter if they are discrete numerical data or continuous numerical data, they can be directly input machine learning model. Unfortunately, categorical data usually represent specific classes or labels. Although some ordinal categorical data have some sense or notion of order, like size of cloth: S is smaller than M which is smaller than L and so on. For most of categorical data, there is no concept of ordering among their values, like different weather categories (sunny, cloudy, snowy). Therefore, categorical data type needs to be transformed into numerical data and then input model.
Currently, there are many different categorical feature transform methods, in this post, four transform methods are listed:
1. Target encoding: each level of categorical variable is represented by a summary statistic of the target for that level.
2. One-hot encoding: assign 1 to specific category and 0 to other category and transform categorical variable to dummy variable.
3. Label encoding: assign ordinal integer to different categorical levels of categorical variable.
4. Entity embedding: map categorical variables in a function approximation problem into Euclidean spaces, and mapping similar values close to each other in the embedding space, and it reveals the intrinsic properties of the categorical variables. Usually the mapping is trained by a neural network during the standard supervised training process, it not only reduces memory usage and speeds up computational efficiency compared with one-hot encoding.

Data Preparation
In order to understand data, it is always necessary to do exploratory data analysis. Because the major objective of this post is to explore how categorical data encoding methods can affect xgboost model performance. The exploratory data analysis results will not present here.
Import all the necessary libraries
from __future__ import division
import pandas as pd
import numpy as np
import datetime
import re
import time
import matplotlib.pyplot as plt
pd.set_option('display.max_columns', 200)
pd.set_option('display.max_rows', 500)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
import xgboost as xgb
from math import sqrt
from sklearn.metrics import mean_squared_error
from scipy.stats import uniform, randint
from sklearn.model_selection import TimeSeriesSplit, cross_val_score, GridSearchCV, RandomizedSearchCV
from sklearn.preprocessing import StandardScaler
import pydot_ng as pydot
from IPython.display import Image
import math
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrixfrom keras.models import Sequential, Model
from keras.layers import Input, Dense, Activation, Reshape
from keras.layers import Concatenate, Dropout
from keras.layers.embeddings import Embedding
from keras.utils import plot_model
from keras.optimizers import SGD
Xgboost with target encoding for categorical variables
In this section, xgboost machine learning model is used to predict the duration between payment date and contact date based on customer attributes. However, the data set include numerical data and categorical data, and target encoding method is used to transform categorical values into numerical values.
target_encode_columns = ['region', 'strategy', 'method', 'mode', 'type', 'status']target = ['pay_cont_dif']target_encode_df = score_df[target_encode_columns + target].reset_index().drop(columns = 'index', axis = 1)target_name = target[0]
target_df = pd.DataFrame()for embed_col in target_encode_columns:
val_map = target_encode_df.groupby(embed_col)[target].mean().to_dict()[target_name]
target_df[embed_col] = target_encode_df[embed_col].map(val_map).values
score_target_drop = score_df.drop(target_encode_columns, axis = 1).reset_index().drop(columns = 'index', axis = 1)score_target = pd.concat([score_target_drop, target_df], axis = 1)
Split data into training data set and test data set.
train_all, test_all = train_test_split(score_target, test_size=0.20, random_state=42)Tune xgboost hyper-parameters. Because our data set is time series data, the k-fold cross validation is not proper for our data set. The time series data spliting technique is adopted to split our data set for cross validation.
params = {'colsample_bytree': uniform(0.7, 0.3),
'gamma': uniform(0, 0.5),
'learning_rate': uniform(0.003, 0.3), # default 0.1
'max_depth': randint(2, 6), # default 3
'n_estimators': randint(100, 250), # default 100
'subsample': uniform(0.6, 0.4)}xgb_model = xgb.XGBRegressor(objective="reg:linear",random_state=42)time_split = TimeSeriesSplit(n_splits = 8)xgb_search = RandomizedSearchCV(xgb_model,param_distributions=params, random_state=42, n_iter=4, cv=time_split, verbose=1, n_jobs=1, return_train_score=True)
Train xgboost model with train data set.
%%time
xgb_search.fit(X_train, y_train)Predict with trained xgboost model, and use RMSE to evaluate model performance.
y_pred = xgb_search.predict(X_test)rms = sqrt(mean_squared_error(y_test, y_pred))
print ('RMSE:', rms)
Although the target variable is continuous data, it is will be very helpful to understand the model performance in different bins of target values. Therefore, the target variable is segmented into different bins, each bin is encoded with integer label. Finally, confusion matrix can be used evaluate model performance in each target variable bin.
def flag_feature(x):
if x >=0 and x < 7:
return 0
elif x >= 7 and x < 14:
return 1
elif x >= 14 and x < 21:
return 2
elif x >= 21 and x < 28:
return 3
elif x >= 28 and x < 35:
return 4
else:
return 5obs_pre = pd.DataFrame(zip(y_test, y_pred))
cols = ['Real', 'Predict']
obs_pre.columns = cols
obs_pre['Real_flag'] = obs_pre['Real'].apply(flag_feature)
obs_pre['Predict_flag'] = obs_pre['Predict'].apply(flag_feature)conf = confusion_matrix(obs_pre['Real_flag'], obs_pre['Predict_flag'])
conf_norm = conf.astype('float') / conf.sum(axis=1)[:, np.newaxis]
conf_norm_round = np.around(conf_norm, decimals=2)fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot()
sns.set(font_scale=1.4, color_codes = 'w')
ax = sns.heatmap(conf_norm, cmap="binary", annot = conf_norm_round, annot_kws={"size": 15}, fmt = '', vmin=0, vmax=1)
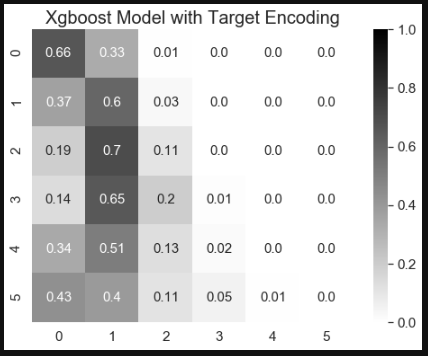
ax.set_title('Xgboost Model with Target Encoding', fontsize=20)
plt.show()
Xgboost with label encoding for categorical variables
Label encoding is used to transform categorical values into numerical values.
encode_columns = ['region', 'strategy', 'method', 'mode', 'type', 'status']encode_df = score_df[encode_columns]encode_df = encode_df.astype('str')
encode_df = encode_df.apply(LabelEncoder().fit_transform)score_encode_drop = score_df.drop(encode_columns, axis = 1)
score_encode = pd.concat([score_encode_drop, encode_df], axis = 1)
Split data into training data set and test data set.
train_all, test_all = train_test_split(score_encode, test_size=0.20, random_state=42)Tune xgboost hyper-parameters.
params = {"colsample_bytree": uniform(0.7, 0.3),
"gamma": uniform(0, 0.5),
"learning_rate": uniform(0.003, 0.3), # default 0.1
"max_depth": randint(2, 6), # default 3
"n_estimators": randint(100, 250), # default 100
"subsample": uniform(0.6, 0.4)}xgb_model = xgb.XGBRegressor(objective="reg:linear", random_state=42)time_split = TimeSeriesSplit(n_splits = 8)xgb_search = RandomizedSearchCV(xgb_model, param_distributions=params, random_state=42, n_iter=4, cv=time_split, verbose=1, n_jobs=1, return_train_score=True)
Train xgboost model with train data set.
%%time
xgb_search.fit(X_train, y_train)Predict with trained xgboost model, and use RMSE to evaluate model performance.
y_pred = xgb_search.predict(X_test)
rms = sqrt(mean_squared_error(y_test, y_pred))
print ('RMSE:', rms)Confusion matrix to understand model performance in each target variable bin.
def flag_feature(x):
if x >=0 and x < 7:
return 0
elif x >= 7 and x < 14:
return 1
elif x >= 14 and x < 21:
return 2
elif x >= 21 and x < 28:
return 3
elif x >= 28 and x < 35:
return 4
else:
return 5obs_pre = pd.DataFrame(zip(y_test, y_pred))
cols = ['Real', 'Predict']
obs_pre.columns = cols
obs_pre['Real_flag'] = obs_pre['Real'].apply(flag_feature)
obs_pre['Predict_flag'] = obs_pre['Predict'].apply(flag_feature)conf = confusion_matrix(obs_pre['Real_flag'], obs_pre['Predict_flag'])conf_norm = conf.astype('float') / conf.sum(axis=1)[:, np.newaxis]conf_norm_round = np.around(conf_norm, decimals=2)fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot()
sns.set(font_scale=1.4, color_codes = 'w')
ax = sns.heatmap(conf_norm, cmap="binary", annot = conf_norm_round, annot_kws={"size": 15}, fmt = '', vmin=0, vmax=1)
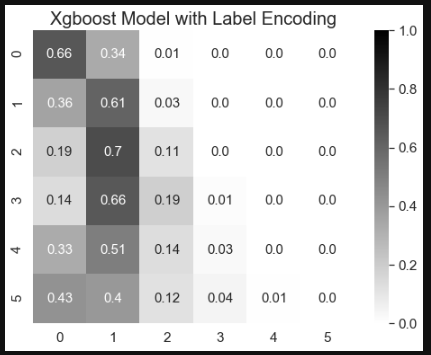
ax.set_title('Xgboost Model with Label Encoding', fontsize=20)
plt.show()
Xgboost with one-hot encoding for categorical variable
One hot encoding is used to transform categorical features.
onehot_columns = ['region', 'strategy', 'method', 'mode', 'type', 'status']onehot_df = score_df[onehot_columns]onehot_df = pd.get_dummies(onehot_df, columns = onehot_columns)score_onehot_drop = score_df.drop(onehot_columns, axis = 1)
score_onehot = pd.concat([score_onehot_drop, onehot_df], axis = 1)
Split data into training and test data set.
train_all, test_all = train_test_split(score_onehot, test_size=0.20, random_state=42)Tune xgboost hyper-parameters.
params = {"colsample_bytree": uniform(0.7, 0.3),
"gamma": uniform(0, 0.5),
"learning_rate": uniform(0.003, 0.3), # default 0.1
"max_depth": randint(2, 6), # default 3
"n_estimators": randint(100, 250), # default 100
"subsample": uniform(0.6, 0.4)}xgb_model = xgb.XGBRegressor(objective="reg:linear", random_state=42)time_split = TimeSeriesSplit(n_splits = 8)xgb_search = RandomizedSearchCV(xgb_model, param_distributions=params, random_state=42, n_iter=4, cv=time_split, verbose=1, n_jobs=1, return_train_score=True)
Train xgboost model with train data set.
%%time
xgb_search.fit(X_train, y_train)Predict with trained xgboost model and evaluate mode with RMSE.
y_pred = xgb_search.predict(X_test)
rms = sqrt(mean_squared_error(y_test, y_pred))
print ('RMSE:', rms)Confusion matrix to understand model performance in each target variable bin.
def flag_feature(x):
if x >=0 and x < 7:
return '0-7'
elif x >= 7 and x < 14:
return '7-14'
elif x >= 14 and x < 21:
return '14-21'
elif x >= 21 and x < 28:
return '21-28'
elif x >= 28 and x < 35:
return '28-35'
else:
return '>35'obs_pre = pd.DataFrame(zip(y_test, y_pred))
cols = ['Real', 'Predict']
obs_pre.columns = cols
obs_pre['Real_flag'] = obs_pre['Real'].apply(flag_feature)
obs_pre['Predict_flag'] = obs_pre['Predict'].apply(flag_feature)conf = confusion_matrix(obs_pre['Real_flag'], obs_pre['Predict_flag'])
conf_norm = conf.astype('float') / conf.sum(axis=1)[:, np.newaxis]
conf_norm_round = np.round(conf_norm, decimals = 2)fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot()
sns.set(font_scale=1.4, color_codes = 'w')
ax = sns.heatmap(conf_norm, cmap="binary", annot = conf_norm_round, annot_kws={"size": 15}, fmt = '', vmin=0, vmax=1)
#ax.set(xlabel=class_dict)
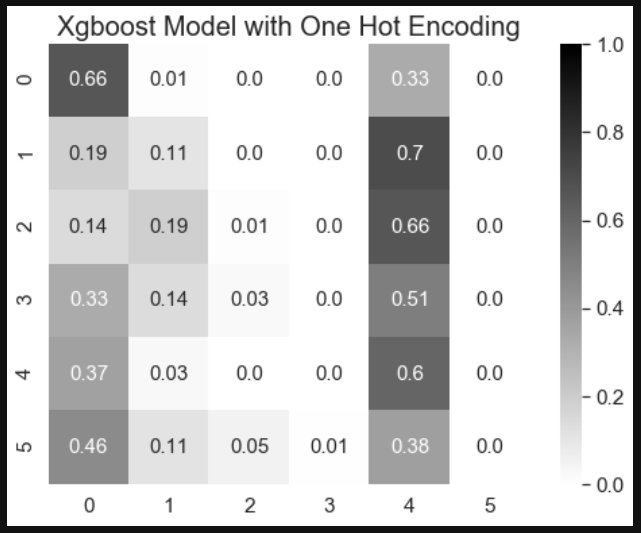
ax.set_title('Xgboost Model with Label Encoding', fontsize=20)
plt.show()
Neural network is used to trained entity embedding weighted matrix for categorical variables
Split data set into training, validation and test data sets.
X_train_first, X_test, y_train_first, y_test = train_test_split(score_df[features], score_df[target], test_size=0.2, random_state=42)X_train, X_val, y_train, y_val = train_test_split(X_train_first, y_train_first, test_size=0.2, random_state=42)
Scalar Numerical variables of data set.
scalar_features = ['tenure', 'score', 'credit', 'amount', 'date_dif']scalar = StandardScaler()
for scalar_feature in scalar_features:
scalar.fit(X_train[scalar_feature].values.reshape(-1,1))
X_train[scalar_feature] = scalar.transform(X_train[scalar_feature].values.reshape(-1,1))
scalar.fit(X_val[scalar_feature].values.reshape(-1,1))
X_val[scalar_feature] = scalar.transform(X_val[scalar_feature].values.reshape(-1,1))
scalar.fit(X_test[scalar_feature].values.reshape(-1,1))
X_test[scalar_feature] = scalar.transform(X_test[scalar_feature].values.reshape(-1,1))scalar.fit(y_train)
y_train = scalar.transform(y_train)
y_val = scalar.transform(y_val)
Checking missing values.
missing_df = score_df[features + target].isnull().sum(axis = 0).reset_index()missing_df.columns = ['variable','missing values']missing_df['filling factor (%)'] = (score_df[features + target].shape[0] - missing_df['missing values']) / score_df[features + target].shape[0] * 100
missing_df.sort_values('filling factor (%)').reset_index(drop = True)
Categorical Features Embedding Preparation
Understand categorical features and their cardinality for each categorical variable.
embed_cols = [i for i in X_train.select_dtypes(include = ['object'])]for i in embed_cols:
print (i, score_df[i].nunique())
Categorical variables to list format so then to match the network structure.
def preproc(X_train, X_val, X_test):
input_list_train = []
input_list_val = []
input_list_test = []
for c in embed_cols:
raw_vals = np.unique(X_train[c])
val_map = {}
for i in range(len(raw_vals)):
val_map[raw_vals[i]] = i
input_list_train.append(X_train[c].map(val_map).values)
input_list_val.append(X_val[c].map(val_map).fillna(0).values)
input_list_test.append(X_test[c].map(val_map).fillna(0).values)
other_cols = [c for c in X_train.columns if (not c in embed_cols)]
input_list_train.append(X_train[other_cols].values)
input_list_val.append(X_val[other_cols].values)
input_list_test.append(X_test[other_cols].values)
return input_list_train, input_list_val, input_list_testBuild Neural Network
input_models = []
output_embeddings = []
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']for categorical_var in embed_cols:
#rename categorical variables which will be used in keras embedding layer
cat_emb_name = categorical_var.replace(" ", "") + "_Embedding"
#define embedding size
no_of_unique_cat = X_train[categorical_var].nunique()
embedding_size = int(min(np.ceil((no_of_unique_cat)/2), 50))
#one embedding layer for each categorical variable
input_model = Input(shape = (1,))
output_model = Embedding(no_of_unique_cat, embedding_size, name = cat_emb_name)(input_model)
output_model = Reshape(target_shape = (embedding_size,))(output_model)
#appending all the categorical inputs
input_models.append(input_model)
#appending all the embeddings
output_embeddings.append(output_model)#other numerical data columns
input_numeric = Input(shape = (len(X_train.select_dtypes(include=numerics).columns.tolist()),))
embedding_numeric = Dense(128)(input_numeric)
input_models.append(input_numeric)
output_embeddings.append(embedding_numeric)#concatnate altogether
output = Concatenate()(output_embeddings)
output = Dense(1000, kernel_initializer = 'uniform')(output)
output = Activation('relu')(output)
output = Dropout(0.4)(output)
output = Dense(512, kernel_initializer = 'uniform')(output)
output = Activation('relu')(output)
output = Dropout(0.3)(output)
output = Dense(1, activation = 'sigmoid')(output)
#output = Dense(1, activation = 'sigmoid')(output) # RMSE: 10.536. since our target is conitinous number it should be regression rather than sigmoidmodel = Model(inputs = input_models, outputs = output)
#model.compile(loss = 'mean_squared_error', optimizer = 'Adam', metrics = ['mse', 'mape'])
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss = 'mean_squared_error', optimizer = opt, metrics = ['mse', 'mape'])
Neural Network Architecture
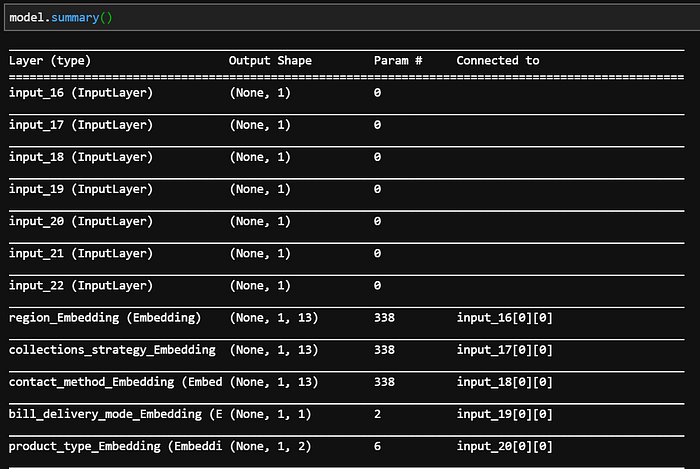
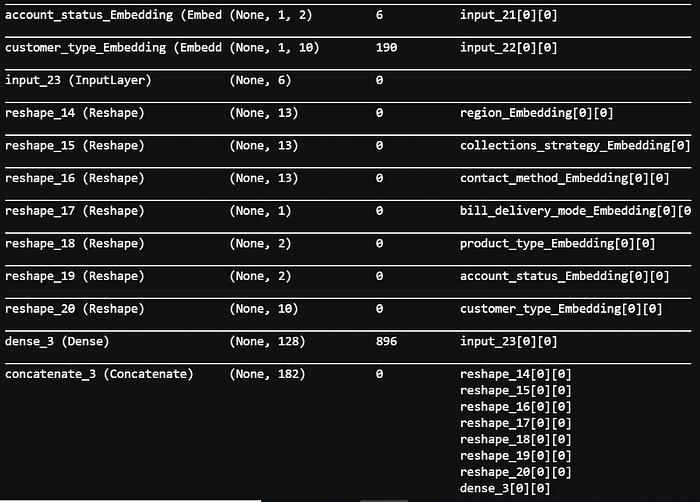
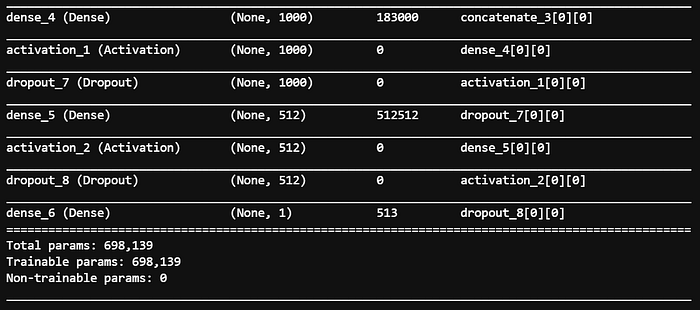
Train neural network model
X_train_list, X_val_list, X_test_list = preproc(X_train, X_val, X_test)%%time
history = model.fit(X_train_list, y_train, validation_data = (X_val_list, y_val), epochs = 100, batch_size = 512, verbose = 2)
Predict with neural network model and evaluate network model with RMSE
y_pred = model.predict(X_test_list)
y_pred = scalar.inverse_transform(y_pred)rms = sqrt(mean_squared_error(y_test, y_pred))
print ('RMSE:', rms)
Xgboost with entity embedding for categorical variables
Get entity embedding weighted matrix of categorical variables from neural network.
embed_cols = ['region', 'strategy', 'method', 'mode', 'type', 'status']score_emb_xgb = score_dffor embed_col in embed_cols:
val_map = {}
raw_vals = np.unique(score_emb_xgb[embed_col])
for i in range(len(raw_vals)):
val_map[raw_vals[i]] = i
col_name = embed_col + '_label'
score_emb_xgb[col_name] = score_emb_xgb[embed_col].map(val_map).values
Map each entity embedding value from neural network back to original categorical level of each categorical variable.
for col in embed_cols:
weight_embed = col + '_Embedding'
weight_df = pd.DataFrame(model.get_layer(weight_embed).get_weights()[0]).reset_index()
for i in weight_df.columns:
if i != 'index':
sub_dict = dict(zip(weight_df['index'],weight_df[i]))
col_name_label = col + '_label'
col_name = col + '_' + str(i)
score_emb_xgb[col_name] = score_emb_xgb[col_name_label].map(sub_dict).valuesembed_label_cols = []
for i in embed_cols:
col_name = i + '_label'
embed_label_cols.append(col_name)drop_cols = embed_cols + embed_label_colsscore_emb_xgb_less = score_emb_xgb.drop(columns=drop_cols, axis=1)
Split data set into training data set and test data set
train_all, test_all = train_test_split(score_emb_xgb_less, test_size=0.20, random_state=42)Tune model hyper parameters
params = {"colsample_bytree": uniform(0.7, 0.3),
"gamma": uniform(0, 0.5),
"learning_rate": uniform(0.003, 0.3), # default 0.1
"max_depth": randint(2, 6), # default 3
"n_estimators": randint(100, 250), # default 100
"subsample": uniform(0.6, 0.4)}xgb_model = xgb.XGBRegressor(objective="reg:linear", random_state=42)time_split = TimeSeriesSplit(n_splits = 8)xgb_search = RandomizedSearchCV(xgb_model, param_distributions=params, random_state=42, n_iter=4, cv=time_split, verbose=1, n_jobs=1, return_train_score=True)
Train model
%%time
xgb_search.fit(X_train, y_train)Predict with neural network model and evaluate network model with RMSE
y_pred = xgb_search.predict(X_test)rms = sqrt(mean_squared_error(y_test, y_pred))
print ('RMSE:', rms)
Confusion matrix to understand model performance in each target variable bin.
def flag_feature(x):
if x >=0 and x < 7:
return '0-7'
elif x >= 7 and x < 14:
return '7-14'
elif x >= 14 and x < 21:
return '14-21'
elif x >= 21 and x < 28:
return '21-28'
elif x >= 28 and x < 35:
return '28-35'
else:
return '>35'obs_pre = pd.DataFrame(zip(y_test, y_pred))
cols = ['Real', 'Predict']
obs_pre.columns = colsobs_pre['Real_flag'] = obs_pre['Real'].apply(flag_feature)
obs_pre['Predict_flag'] = obs_pre['Predict'].apply(flag_feature)conf = confusion_matrix(obs_pre['Real_flag'], obs_pre['Predict_flag'])
conf_norm = conf.astype('float') / conf.sum(axis=1)[:, np.newaxis]
conf_norm_round = np.round(conf_norm, decimals = 2)fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot()
sns.set(font_scale=1.4, color_codes = 'w')
ax = sns.heatmap(conf_norm, cmap="binary", annot = conf_norm_round, annot_kws={"size": 15}, fmt = '', vmin=0, vmax=1)
#ax.set(xlabel=class_dict)
ax.set_title('Xgboost Model with Entity Embedding', fontsize=20)
plt.show()
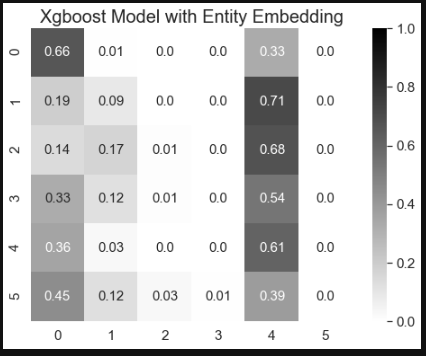
This paper mainly introduce how to use xgboost and neural network model incorporate with different categorical data encoding methods to predict. Two major conclusion were obtained from this study.
- Categorical encoding methods can affect model predictions. In this study, xgboost with target and label encoding methods had better performance on class 0, 1, and 2, and xgboost with one hot and entity embedding methods had better performance on class 0 and 4.
- Xgboost with one hot encoding and entity embedding can lead to similar model performance results. Therefore, entity embedding method is better than one hot encoding when dealing with high cardinality categorical features.
