Background and Theory
After completed two recommendation projects using Amazon Personalize, I have deeply understanding about the mechanism of collaborative filtering recommendation, especially the recommendation method based on cooccurrence. This post will present the detailed algorithm theory and python code about co-occurrence recommendation machine learning algorithm.
Co-occurrence recommendation belongs to collaborative filtering approach. Technically, there are two approaches to build recommender systems: content-based and collaborative filtering. These are intrinsically different methods, content-based approach needs meta-data about the items so that items with similar properties are recommended. Some meta-data for houses are area, year-built, number of bed rooms, number of bath rooms etc. However, it is not necessary to collect these information for collaborative filtering approach, once you have user-item interactive histories data, you are ready to build the recommendation model using co-occurrence.
Why we select user-item interaction data to train recommendation model? Personalized, interesting and useful are major characteristics for a distinct recommender system. User-item interaction data can ensure the greatest extent possible to reflect users’ preference. So then the recommendation based on user-item interaction data can accurately meet users’ taste.
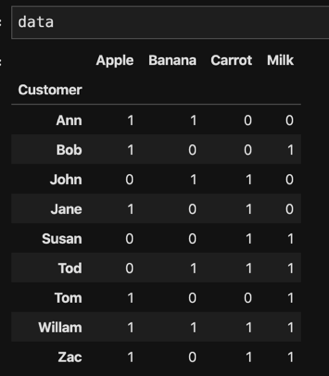
Let us look at the theory behind the recommendation model that use co-occurrence. Assume we have ten users in our database and we have got some user-history data about what they bought from grocery store (Table 1). So Ann bought apple and banana and William bought apple, banana, carrot and milk. This table is the input data of our cooccurrence recommendation model, we can call this matrix as UFM. For the occurred behavior we note it as 1, for the un-occurred behavior we should note it with 0.

Item to Item Recommendations Based on Co-Occurrence Matrix
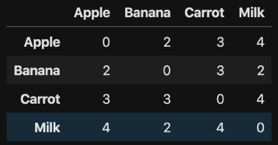
The goal of co-occurrence recommendation machine learning algorithm is finding how many times two food have appeared together in the user historical data. For example, apple and banana appeared together twice in the user Ann and William.

The Co-Occurrence matrix (Table 2) is the cross product between UFM’s transpose matrix and the original. Based on the cooccurrence matrix we can make item to item recommendation. In this toy example:
- For apple: the first recommendation is milk which has the highest weighting value of 4, second recommendation is carrot with the weighting value of 3, and the third recommendation is banana with the weighting value of 2;
- For banana item: the recommendations are carrot, milk and apple;
- For carrot item: the recommendations are milk, apple, and banana;
- For milk item: the recommendations are apple, carrot and banana.
Item to User Recommendations
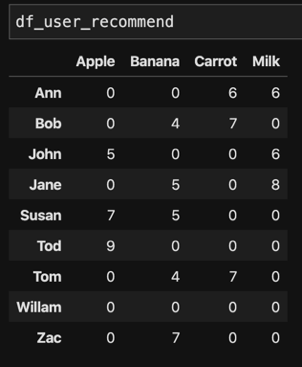
If we want create recommendations for particular user, we can calculate matrix product between UFM and co-occurrence matrix.
For example, the recommendations to Ann we can use product of co-occurrence matrix and the Ann vector of UFM (Table 3).

However, we usually set to zero all items already preferred by the user, and only recommend new items to user. Based on the recommendation matrix (Table 4), we will recommend Carrot and Milk to Ann.

Python code
import pandas as pd
import numpy as np#input data
data = pd.read_csv('data.csv')
data.set_index('Customer', inplace = True)
# calculate co-occurrence matrix
x = np.array(data)
y = np.array(data.T)
co_matrix = np.dot(y,x)
np.fill_diagonal(co_matrix, 0)df_co = pd.DataFrame(co_matrix, columns = ['Apple', 'Banana', 'Carrot', 'Milk'], index = ['Apple', 'Banana', 'Carrot', 'Milk'])df_co
# calculate user recommendation matrix
user_matrix = np.dot(x, co_matrix)
idx = pd.np.nonzero(x)
user_matrix[idx] = 0df_user_recommend = pd.DataFrame(user_matrix, columns = ['Apple', 'Banana', 'Carrot', 'Milk'], index = ['Ann', 'Bob', 'John', 'Jane', 'Susan', 'Tod', 'Tom', 'Willam', 'Zac'])
Python Code for Amazon Personalize
The schema of input file for amazon personalize is required two columns: user and items:
import pandas as pd
import numpy as np
from pandas.api.types import CategoricalDtype
from scipy.sparse import csr_matrixdata = pd.read_csv('data1.csv')
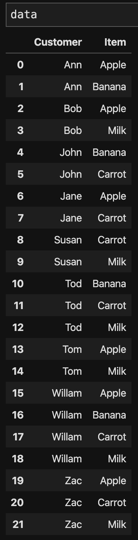
Identify unique categories of user and item, in the meantime order all the categories:
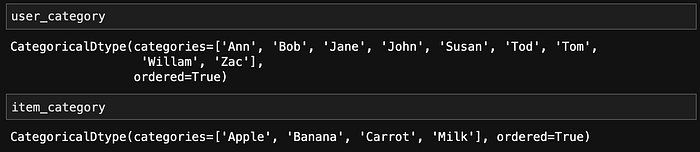
user_category = CategoricalDtype(sorted(data.Customer.unique()), ordered=True)item_category = CategoricalDtype(sorted(data.Item.unique()), ordered=True)
Assign order number to user and item for original data
row = data['Customer'].astype(user_category).cat.codes
col = data['Item'].astype(item_category).cat.codes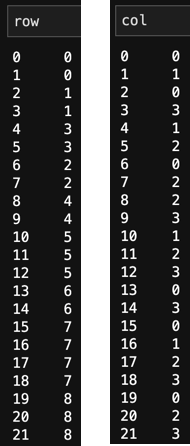
Before create co-occurrence matrix, we need add count column to raw data:
data['Count'] = 1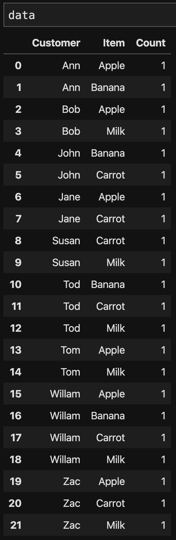
Transform two column raw data frame into user item sparse matrix
sparse_matrix = csr_matrix((data['Count'], (row, col)),shape=(user_category.categories.size,item_category.categories.size))sparse_df = pd.SparseDataFrame(sparse_matrix,index=user_category.categories,columns=item_category.categories,default_fill_value=0)
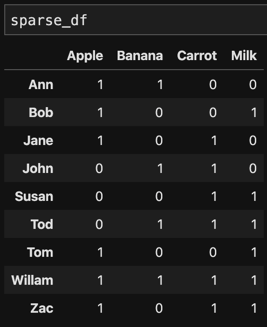
Using sparse matrix create co-occurrence matrix
co_matrix = sparse_matrix.transpose().dot(sparse_matrix)
co_matrix.setdiag(0)
co_df = pd.SparseDataFrame(co_matrix,
index=item_category.categories,
columns=item_category.categories,
default_fill_value=0)
In reality, one user may only buy several items, and rarely buy all the different items. Therefore many zero values appear in co-occurrence matrix. In order to remove these zero value, we need filter out nonzero index in co-occurrence matrix:
idx = pd.np.nonzero(co_matrix)
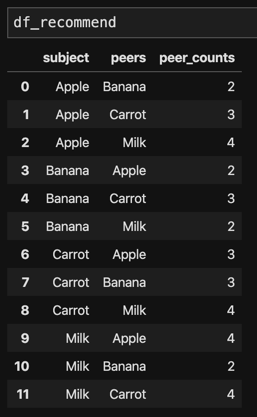
Create subjects and peers list (subject is object need to find recommended items; peers are recommended items to subject):
rows = idx[0]
columns = idx[1]
subjects = [item_id_category.categories[i] for i in rows]
peers = [item_id_category.categories[i] for i in columns]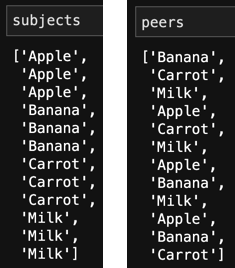
Extract the co-occurrence counts for pair of foods.
ele = co_matrix[idx].tolist()[0]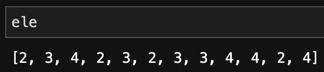
Create final recommend dataframe
df_recommend = pd.DataFrame.from_records(zip(subs, peers, ele), columns = ['subject', 'peers', 'peer_counts'])